Topic Modelling
http://medline.wikispaces.com/Topic+Models+for+Text+Mining
Text Analysis and Topic Models (Overview)
National ICT Australia (NICTA) – Australian National University (ANU)http://www.nicta.com.au/__data/assets/pdf_file/0004/21496/BuntineACML09Tute_4up.pdf
Topic Models and word co-occurrence methods
Recently, a huge body of literature discussing how to extract information from written text has grown. Hence I will just describe four milestones/popular models and their advantages/disadvantages and thus highlight (some of) the main differences (or at least what I think are the main/most important differences).
You mention the “easiest” approach, which would be to cluster the documents by matching them against a predefined query of terms (as in PMI). These lexical matching methods however might be inaccurate due to polysemy (multiple meanings) and synonymy (multiple words that have similar meanings) of single terms.
As a remedy, latent semantic indexing (LSI) tries to overcome this by mapping terms and documents into a latent semantic space via a singular value decomposition. The LSI results are more robust indicators of meaning than individual terms would be. However, one drawback of LSI is that it lacks in terms of solid probabilistic foundation.
This was partly solved by the invention of probabilistic LSI (pLSI). In pLSI models each word in a document is drawn from a mixture model specified via multinomial random variables (which also allows higher-order co-occurences as @sviatoslav hong mentioned). This was an important step forward in probabilistic text modeling, but was incomplete in the sense that it offers no probabilistic structure at the level of documents.
Latent Dirichlet Allocation (LDA) alleviates this and was the first fully probabilistic model for text clustering. Blei et al. (2003) show that pLSI is a maximum a-posteriori estimated LDA model under a uniform Dirichlet prior.
Note that the models mentioned above (LSI, pLSI, LDA) have in common that they are based on the “bag-of-words” assumption – i.e. that within a document, words are exchangeable, i.e. the order of words in a document can be neglected. This assumption of exchangeability offers a further justification for LDA over the other approaches: Assuming that not only words within documents are exchangeable, but also documents, i.e., the order of documents within a corpus can be neglected, De Finetti’s theorem states that any set of exchangeable random variables has a representation as a mixture distribution. Thus if exchangeability for documents and words within documents is assumed, a mixture model for both is needed. Exactly this is what LDA generally achieves but PMI or LSI do not (and even pLSI not as beautiful as LDA).
topicmodels: An R Package for Fitting Topic Models
uments. The tted model can be used to estimate the similarity between documents as well as between a set of specied keywords using an additional layer of latent variables which are referred to as topics. The R package topicmodels provides basic infrastructure for tting topic models based on data structures from the text mining package tm. The package includes interfaces to two algorithms for tting topic models: the variational
expectation-maximization algorithm provided by David M.~Blei and co-authors and an algorithm using Gibbs sampling by Xuan-Hieu Phan and co-authors.http://cran.r-project.org/web/packages/topicmodels/vignettes/topicmodels.pdf
MALLET – MAchine Learning for LanguagE Toolkit
http://mallet.cs.umass.edu/
Learning Relations for Terminological Ontologies from Text
into two sub-tasks: concept extraction and relation learning. We describe an new approach to
learn relations automatically from unstructured text corpus based on one of the probabilistic topic
models, Latent Dirichlet Allocation. We rst provide denition (Information Theory Principle for
Concept Relationship) and quantitative measure for establishing subsumption relation between
concepts. Based on the principle and quantitative measure, another relation called \related”
is derived. We present two relation learning algorithms to automatically interconnect concepts
into concept hierarchies and terminological ontologies with the probabilistic topic models learned,
which are used as ecient dimension reduction techniques in our approach. In our experiment a
total number of 168 set of ontology statements expressed in terms of broader and related relations
are generated using dierent combination of model parameters. The ontology statements are
evaluated by domain experts according to recall, precision and F1 measures. The results show
that the highest precision of the learned ontology is around 86.6% and the lowest is 62.5% when
40 latent classes are used for training the topic models. Structures of learned ontologies s remainstable
when values of the paramters are changed in the ontology learning algorithms.
http://baggins.nottingham.edu.my/~eyx6ww/pub/acm-tkdd.pdf
ParallelTopics: A Probabilistic Approach to Exploring Document
Collections
TopicViz: Interactive Topic Exploration in Document Collections
TIARA: A Visual Exploratory Text Analytic System
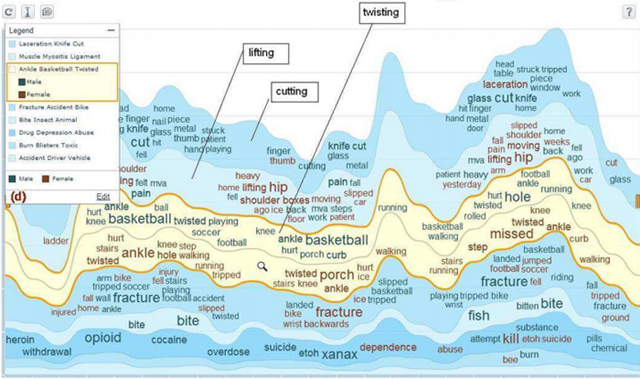
CCHS Authorship